记一次声音训练的尝试
序⾔
之所以有这篇文章的诞⽣,是因为工作业务中探索 AI ⽅向,我选择了声⾳相关的选题。⽬前已知主流的⾳频 ⽣成模型有以下⼏个: RVC, DDSP-SVC, DiffSinger, sovits。我作为⻔外汉,第⼀选择就是选 star 最⾼ 的 sovits, 19k 的 star。对了,这⼏个模型都是⽀持⾳频转⾳频的,不仅仅是⽂字转⾳频。支持⾳频转⾳频也就意味着⽀持 real-time 推理,因为⾳频作为 input,本质上就是⼀种流。该⽂章以下的内容会阐述我是如何训练出想要的⾳频模型。
训练
前置条件
ok,既然完成了调研,那我就事不宜迟着⼿造模型啦,造模型其实就像把⼤象装进冰箱⼀样,只需要三步:
- 打开冰箱(input)
- 把⼤象放进去(train)
- 关闭冰箱(output)
Input
声⾳
既然是声⾳模型,众所都周知,输⼊的肯定是⾳频⽂件了。假如你想训练 Musk 的模型,那就⽤ Musk 的声⾳,但这⾥需要谨慎⼀下,不要使⽤公众⼈物声⾳,可能涉嫌相关问题。所以社恐的我肯定不会⽤⾃⼰的声⾳,我左思右想,找到了⼀位朋友的声⾳。
⾳频
从框架的 GitHub 说明了解到,我需要⼤概 30 分钟左右的⼲声,当然越⻓越好。所谓⼲声,就是纯净⽆背景杂⾳的⼈声。我到底从哪⾥搞这么⻓的⼲声呢,感谢一场会议记录成就了这段佳话。
合适的⾳频
- 我把这⼀个半⼩时的会议视频下载了下来
- 再取视频⽂件内的⾳频,最后得出右边这么⼀个⽂件
- 对了,因为后⾯讨论激烈,我只要了前⼀个⼩时的
- 同时也由衷感谢这位会议的分享者
⾳频⼆次降噪
降噪怎么实现呢?这⾥讲究的是⼀个⼈声与背景分离,⼀不⼩⼼⼜触碰到⼀个新的领域,这个领域其实已经有很成熟的模型。它甚⾄已经有开发好的客⼾端了,真是谢天谢地不⽤折腾。ULTIMATE VOCAL REMOVER V5 没错,它还是深度学习领域的产物。CPU 和 GPU 都⽀持。
这是我当时跑的截图,哪怕是 Mac 的 M2 也贼慢,建议还是⽤ GPU 来跑。 对了,模型有很多,但我当时不够聪明,没选最好的,有需要建议⾃⾏选择,按 Overall SDR 最 ⾼分来选就完事了我们的这个场景。
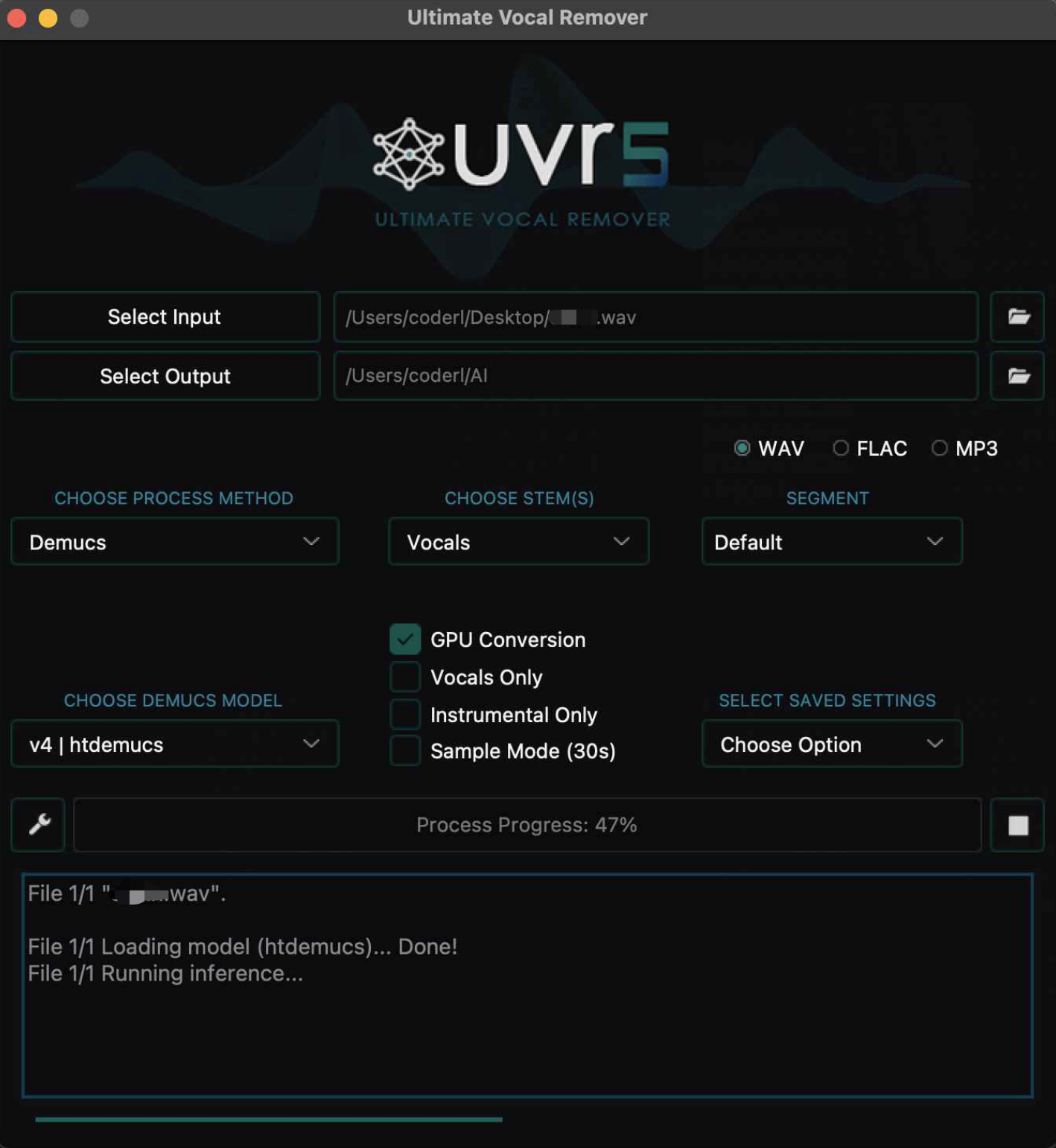
最后推理出来的产物就是这些,会有纯⼈声和纯背景声,不少⼈喜欢拿来把歌曲的伴奏和⼈声分离。

⾳频分割
得,⼲声也有了,真是满满的⼲劲咧。
为什么⾳频还要分割?因为不分割的话,显卡的显存不够,如果把⼀个⼩时的视频丢进去炼丹,相当于在玩⽕。把⾳频拆分成 3s ~ 6s 的散⽂件,这样就显卡就不会吃不消⽽且因为⼩吞吐也快了,同时也不影响效果。
拆分的话⽅式有很多,我⽤的是 Audio Slicer。把 Mini Length 设置成 30000ms 就好了,其他默认。
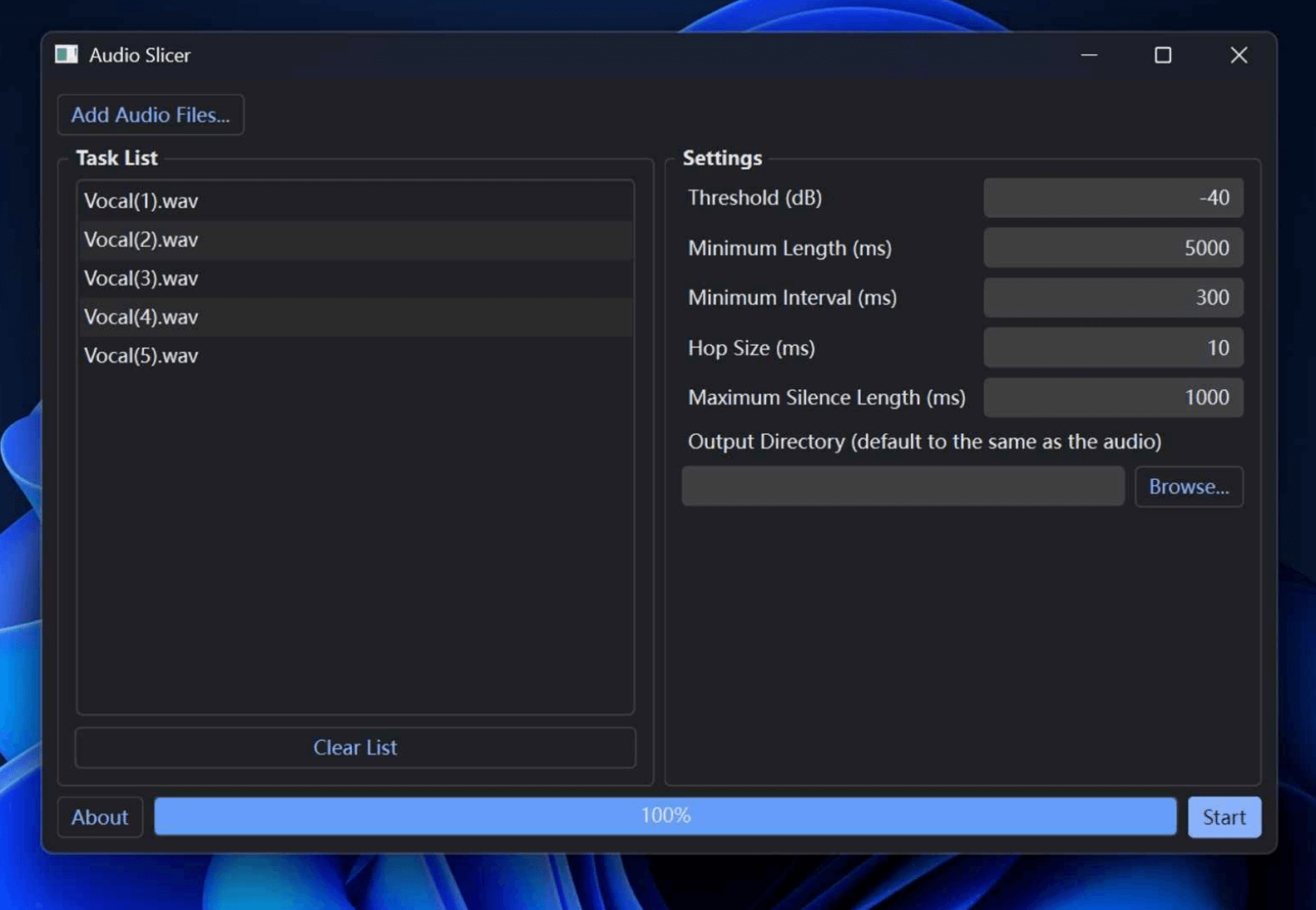
最终终于得到了这堆真正能⽤的 input 了
Train
环境
训练要准备的前置条件,⾸当其冲的当然就是训练的环境了,鉴于本地环境不现实(等申请到带显卡的主机且采购回来且到我这⾥,我可能已经离开了这家公司),我的⽬光放到了远程环境,选择有很多,⽐如 Vast,AWS,Colab...... 最终我选择的是 Google Colab,因为本就不熟悉 Python 的我根本就不想进⼀台容器⾥⾯浪费时间搭 环境,当然,Colab 也是这些⾥⾯性价⽐最低的。
框架
最上⾯就说啦,star 即正义,所以我选的 sovits。值得⼀提的是这仓库基本都是⼆次元开发者维护, ⽽且⼤部分是 Location China 的贡献者,真是感谢这些⼆次元⽤爱推动发展。(因为他们想听他们喜欢的动漫⻆⾊唱歌)
在此我也恳请你认真阅读且遵守仓库链接最底部的内容,这也是⼀个很重要的前置条件,同时本文也严格遵守这些内容,本文仅为记录,仅供学术参考,不对其他使用方式负责!
准备好期待的表情
万事俱备
让我们来开始⾛弯路吧。
让框架跑起来
既然我们选择了 Colab,那就可以安⼼的做⼀个伸⼿党,开源仓库根⽬录就⾃带了 ipynb 的执⾏⽂本。实际上也有⼈整理出更好的版本,甚⾄是中⽂的。有更多需求可以⾃⼰ Google 找就完事了。
配置 & 执⾏
- 连接 GPU
- 挂载你的⾕歌云盘
- 上传那堆 input 到你的⾕歌云盘
- 配置那堆 input 的路径
- Input 的⾳频重新采样处理
- ⽣成训练集
- ⽣成 hubert 和 f0
- 配置训练输出的⽂件(⽇志,模型)路径
- 开始 Tensorboard 可视化训练
漫⻓的等待
很开⼼,⾛到了这⼀步,等待也是幸福的
我⽤的是免费的 Colab 算⼒,GPU 是祖传的 Tesla T4
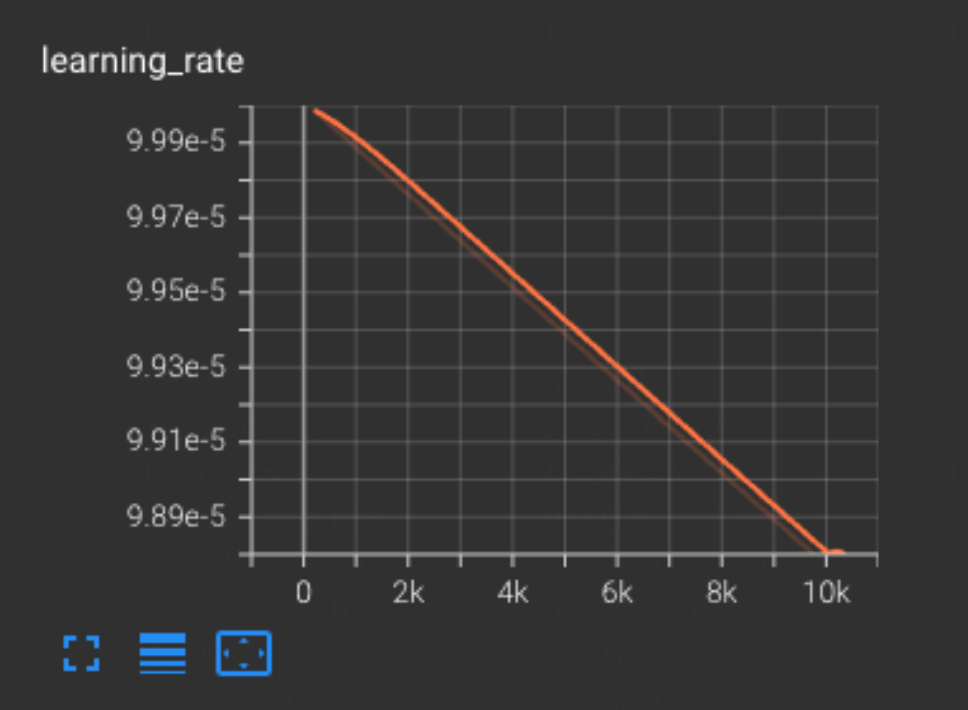
⼀个 Epoch 要花费的时间可能是五六分钟,所以基本 4000step 就要等⼀个下午的时间。但其实 4000 step 出来的模型效果已经不会很差了,从可视化的⾯板来看。

钞能⼒
实不相瞒,我能跑出 12800step 是因为我忍不住充值,不⽌开了订阅,还买了算⼒,上了 A100。

炫耀显存

Output
换⼀条路
当我跑了 12800step 之后我发现 sovits 的效果还是能很容易听出来是⽣成的,所以我决定尝试别的框 架,毕竟钞能⼒触发了,不⽤也是浪费。
重复⼀遍
这⼀次我选的 RVC,它有很优秀的底模,⽽且仍然在维护的状态,这是我选择它作为备选的原因。
同样的,也有执⾏的 book,所以你只需要耐⼼的按着⾥⾯的指引再⾛⼀遍流程就⾏了,input 还是那些 input,我就不再过多的赘述了。
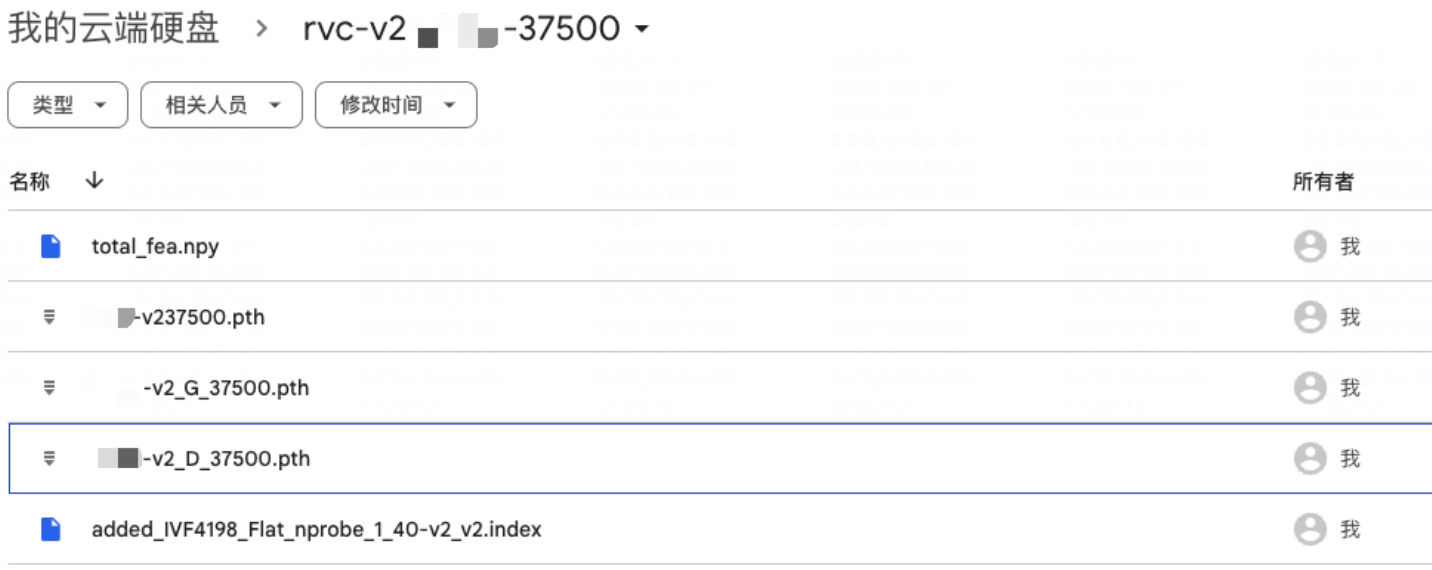
有了 A100 我也更加放肆,这次我直接跑了 37500step,具体数据也只能参考⽇志了,什么图都没存。

神丹
这是我最终得到的模型
Sovits
RVC
推理
如此这般,⼗分简单
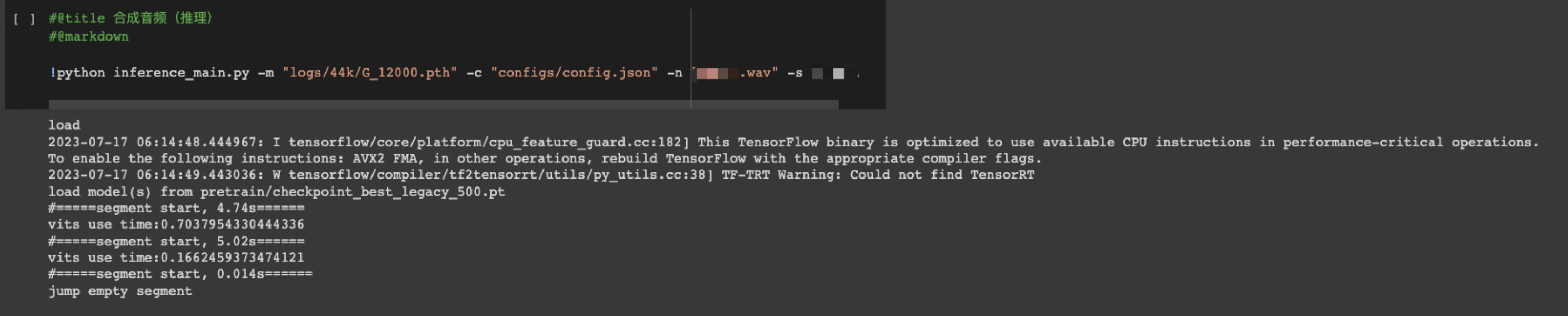
输⼊样本,输出结果。以下内容请在家长陪同下收听:)
| Input | Output | 实际 | |
|---|---|---|---|
| sovits | 实际没读过,请根据训练集⾃⾏脑补 | ||
| RVC | 同上 | ||